Titulo: Programa para
Compactação de Dados Utilizando Códigos de Huffman.
Nome dos autores: Getúlio
A. de Deus Júnior, Diego Vidier Oda Arruda e Rodrigo Silva Góes.
Unidade Acadêmica onde o trabalho foi desenvolvido: Escola de Engenharia Elétrica e
de Computação (EEEC).
E-mail (do autor principal): getulio@eee.ufg.br
Palavras-Chave: Compactação
de Dados, Códigos de Huffman, Lempel-Ziv.
Introdução:
Basicamente
compactar dados significa reduzir o seu tamanho original de tal maneira que
possamos reconstituí-lo originalmente sem perda de informação. Ela pode ser
aplicada em arquivos de dados, documentos, imagens, etc. [1].
As
duas técnicas mais utilizadas é a de código estatístico e a de supressão de
seqüências repetitivas. Vamos fazer uma descrição sobre estas duas técnicas. O
mais popular método de compactação que utiliza código estatístico é o Código de
Huffman que consiste em traduzir pedaços de tamanho fixo em símbolos de tamanho
variável [2]. Ele procura uma maneira de gerar códigos para os símbolos de
entrada cujo tamanho deste código em bits é aproximadamente log2 (probabilidade do símbolo), onde a
probabilidade do símbolo é a freqüência relativa de ocorrência de um símbolo
dado expresso em probabilidade.
Material e Método
(Metodologia):
Na
implementação de nosso compactador utilizando Código de Huffman [2], tomamos um
arquivo .txt que desejamos compactar e geramos um arquivo .huf cujo conteúdo é
inteligível apenas quando aplicamos o processo inverso o que chamamos de
descompactação.
Como
propósito de pesquisa, optamos por fazer uma filtragem do arquivo texto
inicial, que consiste basicamente em considerar somente caracteres maiúsculos;
ou seja, qualquer texto que utilize nosso programa só poderá ser processado,
para nível de pesquisa, se todos seus caracteres forem maiúsculos. Entretanto,
o compactador de Huffman implementado funciona tanto para caracteres maiúsculos
como para caracteres minúsculos.
Um
formulário no programa implementado a partir da leitura de um texto retorna uma
estatística de freqüência de caracteres. Para obter uma estatística fixa,
fizemos uma compilação de cem arquivos textos diferentes das mais diversas
fontes, em língua portuguesa, aplicando o programa implementado, cujos
resultados foram tabulados e cuja tabulação será utilizada para se estimar a
média em percentagem de caracteres de um texto qualquer em língua portuguesa.
Resultados e
Discussão:
Como
proposta para implementação do compactador de dados dividimos o programa em
dois formulários principais [3]. O primeiro formulário é mostrado na Fig. 1
(a). O programa foi implementado em linguagem Borland Builder C/C++ [4].
|
|
|
|
(a) |
(b) |
|
Figura 1: Programa implementado. |
|
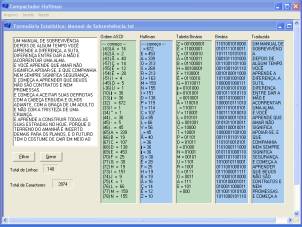
A
Fig. 1 (a) mostra dinamicamente o processo de compactação e descompactação,
desde a filtragem dos dados, montagem da estatística ordenada por código ASCII,
montagem da estatística ordenada por freqüência de incidência, montagem da
tabela de Huffman, montagem da cadeia de bits, até a descompactação a partir da
leitura da árvore de Huffman montada dinamicamente e da leitura seqüencial da
cadeia de bits.
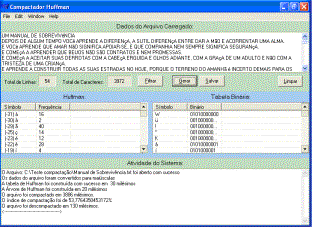
O
outro formulário, mostrado na Fig. 2 (b), apresenta o processo de compactação
nos retornando os índices de compactação, o tempo levado para montar a árvore
de Huffman, o tempo levado para montar a cadeia de bits, o arquivo .huf gerado
e o tempo de descompactação.
Para
arquivos textos maiores que 40 KB, o compactador de arquivos implementado,
apresentou uma ligeira demora na compactação, e na descompactação que tende a
crescer exponencialmente com o aumento linear do arquivo. Isso porque ao
compactarmos, temos que fazer sucessivas leituras na árvore de Huffman para
montarmos a cadeia de caracteres. Ao descompactarmos, temos que fazer o
processo inverso com a sobrecarga das comparações com o cabeçalho.
Constatamos
um problema inerente ao Código de Huffman: a complexidade de descompactação [2].
O método básico para interpretar cada código é ler cada bit da seqüência.
Operacionalmente, uma decisão lógica é feita para cada bit. Em geral,
descompactação com símbolos de tamanho variável provê um custo/desempenho em
decadência à medida que o volume de dados aumente.
Testes
realizados:: Realizamos alguns
testes comparativos utilizando três compactadores comerciais e o nosso programa
que utiliza o Código de Huffman, com a finalidade de comparar os índices de
compactação [3].
Os
compactadores utilizados foram: Gzip, Winrar, Winzip e Huffman. Além de outros
arquivos fontes, utilizamos dois arquivos em especial para teste: Manual de
Sobrevivência.txt e o arquivo Programa.cpp. Os resultados obtidos estão na
tabela I.
Tabela I - Comparação
índices de compactação médios.
Nº
|
Arquivo
|
Tamanho
(bytes)
|
Gzip
(bytes)
|
WinRar
(bytes)
|
Winzip
(bytes)
|
Huffman
(bytes)
|
1.
|
.txt
|
3.972
|
1.721
|
1.827
|
1.855
|
3.715
|
2.
|
.cpp
|
4.105
|
1.469
|
1.529
|
1.575
|
2.557
|
3.
|
.log
|
16.497
|
1.541
|
1.578
|
1.664
|
9.842
|
4.
|
.htm
|
5.419
|
1.809
|
1.879
|
1.909
|
1.075
|
5.
|
.obj
|
6.642
|
2.103
|
2.205
|
2.256
|
2.450
|
Para
o primeiro arquivo (Manual de Sobrevivência.txt) obtivemos o melhor índice de
compactação para o programa Gzip, exatamente 43,33 %. Em seguida, vem o Winrar
com 45,50%, depois o Winzip com 48,92% e o Huffman com 93,53%. Para o segundo
arquivo (Programa.cpp) tivemos um índice de compactação para o código de
Huffman de 62,28%. Em seguida, vem o Gzip com índice de 35,78%, depois o Winrar
com 37,25% e o Winzip com 38,37%.
Conclusão:
Percebemos
que, no primeiro caso, o Código de Huffman teve um índice de compactação em
termos absoluto e relativo pior que no segundo caso. Isto se deve a dois
motivos: primeiramente quanto menor a quantidade de símbolos diferentes entre
si, melhor será o índice de compactação para o Compactador de Huffman. Não é o
que acontece no primeiro arquivo, cujo texto está repleto de símbolos
diferentes num universo total de caracteres relativamente pequeno, algo como
3.972 caracteres. Em segundo lugar, o código de Huffman, estabelece a menor
cadeia de bits para o símbolo que apareceu a maior quantidade de vezes. Obtemos
um arquivo com índice de compactação menor, quanto maior for a quantidade de
vezes que esse símbolo apareça. Isto é o que ocorre num arquivo.cpp, pois neste
arquivo, temos uma espantosa soma de espaços que o compactador de Huffman
reduziu extraordinariamente bem.
Referências
Bibliográficas:
[1]
G. HELD. Comunicação de Dados. Rio de Janeiro: Editora Campus, 1999.
[2]
J. L. SZWARCFITER e L. MARKENZON. Estrutura de dados e seus algoritmos. Rio de
Janeiro: Editora LTC, 1994.
[3]
D. V. O. Arruda e R. S. Góes, Compactação
de Dados, Projeto Final de Curso, Universidade Federal de Goiás, 2003.
[4] B. R. PREISS. Data
Structures and Algorithms with object – oriented desing patterns in C++. New York: Editora John Wiley & Sons,
Inc, 1999.
[5]
J. ZIV e A. LEMPEL. Compression of individual sequences via variable-rate
coding. IEEE Transactions on
Information Theory, Vol. it-24, n 5. september 1978, 530 a 536.